Reliability Means Being Able to Explain What Happened
Why trustworthy GenAI requires audit trails, decision logs and execution timelines.

The reliability mistake GenAI teams keep making
Most conversations about AI reliability revolve around accuracy.
Did the model hallucinate?
Did it give the right answer?
Did it follow instructions?
That framing is dangerously incomplete.
In real systems, reliability is not defined by how often things work.
It is defined by what happens when they don’t.
When AI systems start:
Approving actions
Generating outputs that trigger workflows
Touching customer data
Influencing decisions
they become part of the operational fabric of a business.
At that point, “the model got confused” is not an acceptable explanation.
Why production systems do not tolerate black boxes
Every serious production system is built on a simple assumption:
Every important decision must be explainable after the fact.
That is why banks have transaction logs.
That is why cloud platforms have audit trails.
That is why enterprise software has role-based access control and changes history.
These mechanisms exist not because failures are rare - but because they are inevitable.
GenAI systems are now:
Making recommendations
Executing tasks
Routing information
And shaping outcomes
Yet most teams cannot answer basic questions about what their AI did yesterday.
That is not a technical inconvenience.
It is an existential risk to trust.
Why accuracy is the wrong reliability metric
Accuracy measures whether an output looks correct.
Reliability measures whether a system can be trusted.
Those are not the same.
An AI system can:
Give correct answers
Follow prompts
Pass benchmarks
and still be completely unreliable in production.
Why?
Because when it fails, nobody knows why.
Was it:
Bad input
A tool error
Corrupted memory
A fallback chain
Or a policy misfire?
Without that information, teams cannot:
Fix bugs
Prevent repeats OR
Demonstrate compliance
The system becomes a liability.
What an AI incident really looks like
Imagine this scenario:
An AI agent:
Processes customer data
Calls an internal tool
Generates a report and
Sends it to the wrong party
A regulator asks:
What data did it access?
Why was that data included?
Who approved the action?
What safeguards were in place?
If the only available artifact is:
a prompt
and a final output
the organization has no defense.
There is no way to prove:
What the AI saw
What it decided or
What controls were applied
Trust collapses instantly.
What real reliability requires
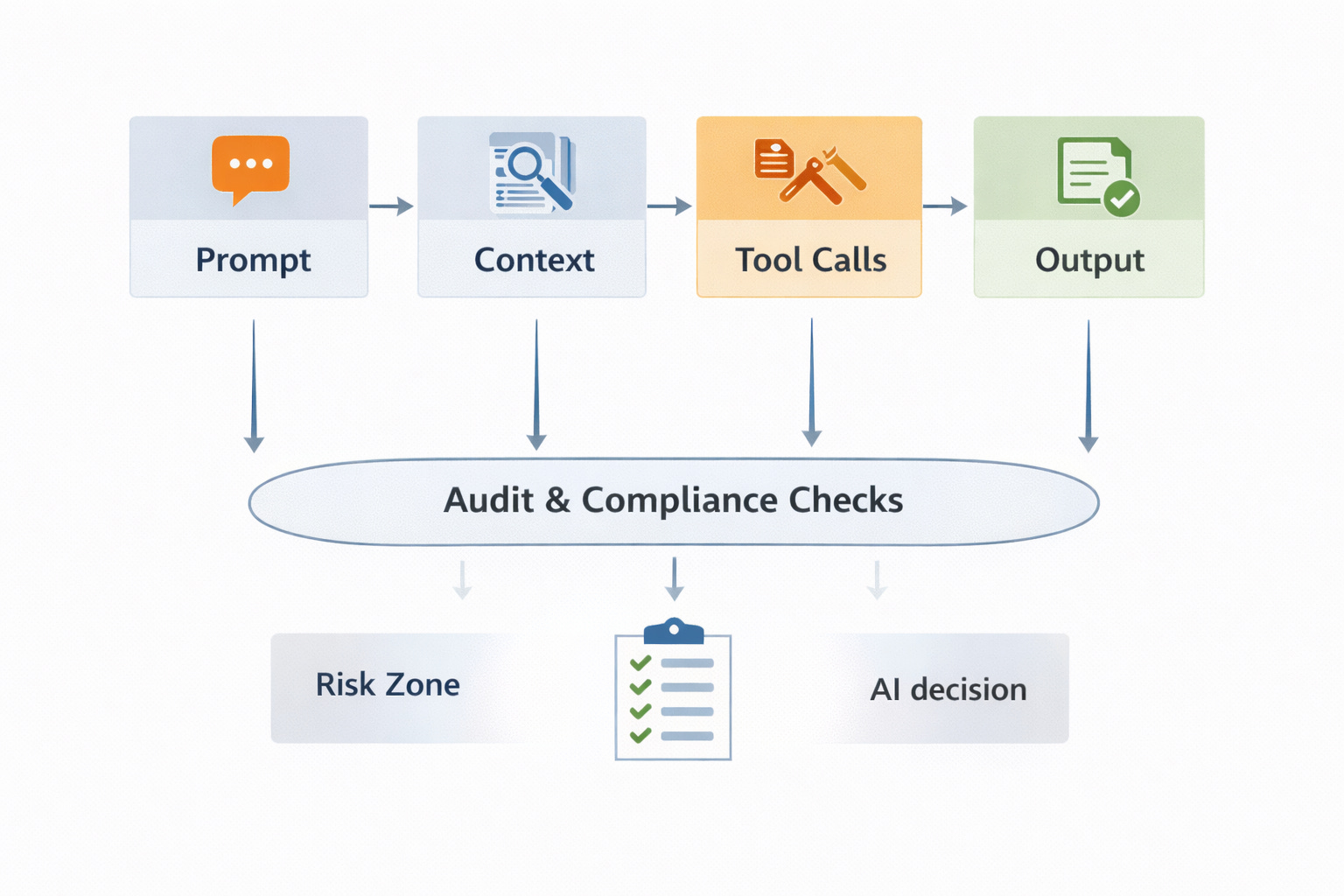
In traditional systems, reliability is built on four pillars:
Execution logs
State history
Decision trails
Policy enforcement
These exist so that every important action can be reconstructed.
Agentic AI needs the same.
For every meaningful AI action, you need to know:
Which prompt was used
What context was included
Which tools were called
What memory was read or written
What policies applied and
What output was produced
That is not optional.
It is the minimum bar for operating a system that affects real people and data.
Why this is an executive-level issue
Once AI systems start touching:
Financial decisions
Regulated data or
Customer outcomes
they become board-level risks.
Executives do not ask:
“Was the model good?”
They ask:
“Can we prove what happened?”
If the answer is no, the system will not be allowed to scale.
Why trust cannot exist without evidence
Trust in software comes from:
Visibility
Control and
Accountability
Without logs, traces and audits, AI becomes a black box that nobody can defend.
That is not how enterprises operate.
They require:
Explainability
Governance and
Forensic capability
GenAI must meet the same standard.
The control-plane shift
We are entering a phase where:
AI systems are no longer tools.
They are operators.
Operators must be governed.
That requires:
Immutable logs
Decision timelines
Policy enforcement and
Auditability
Without those, reliability is an illusion.
Open question
If your AI system caused a serious incident tomorrow, could you reconstruct exactly what it did - step by step - or would you be left with nothing but a prompt and a guess?
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.