
(Watch the video above or read the original blog below - either way, you’ll gain a clearer understanding of how AI really scales.)
Every AI vendor likes big numbers: a projected $100B+ inference market, chips boasting 1000+ TFLOPS, 100 GB/s of bandwidth. But spec sheets lie. In practice, real-world throughput and cost depend on bottlenecks hidden in the system, not just raw silicon. Analysts already value the inference market at ~$106B in 2025, heading past ~$150B by 2027 - but that scale will break the budgets of any company that blindly pours money into GPUs. The key lesson: efficiency beats brute force. Each wasted memory fetch, network hop or repeated computation is dollars down the drain.
To win the inference “race”, you need to eliminate waste in every layer. That means smarter hardware choices and software optimizations. It means rethinking attention algorithms, caching, quantization and even network architecture. Below we pull together the best insights and analogies (the “ELI5” moments) from our research to show exactly where the real costs hide - and how to slay them.
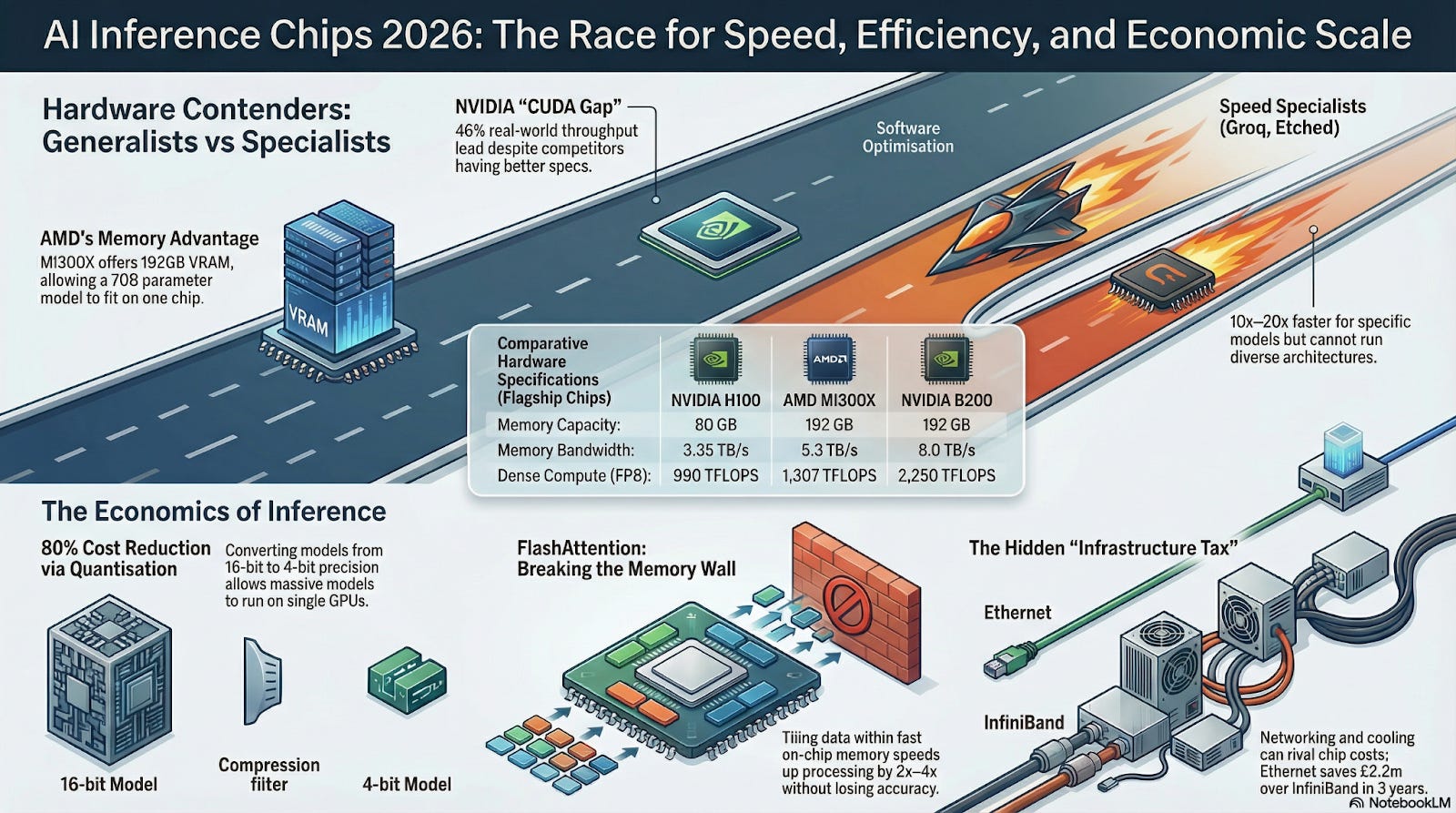
Generalist vs. Specialist Chips: A Swiss Army Knife vs. a Race Car
Inference silicon is splitting into two camps: generalist GPUs with mature ecosystems (e.g. NVIDIA’s Hopper/Blackwell, AMD’s MI300) vs specialist accelerators built for one workload (e.g. Groq, SambaNova, Neural Processing Units). On paper, specialists can have higher raw specs - but in production, the story is different. A GPU’s flexibility and software stack often let it deliver more real work. For example, even though AMD’s MI300X has much larger memory (192 GB HBM3) and higher TFLOPS than NVIDIA’s H100, NVIDIA’s optimized stack still outperforms MI300X in real tests. In one 8‑GPU benchmark, an NVIDIA H100 setup delivered ~46% higher inference throughput than an equal MI300X system. This “CUDA gap” - the extra performance NVIDIA gets from its mature software - is huge.
A GPU is like a Swiss Army knife - it’s not the fastest thing on a racetrack, but it can work on any surface. A specialized AI chip is like a Formula 1 car: insanely fast on a smooth track (a fixed model), but useless off-road (when your model or pipeline changes).
In practice, most enterprises stick with NVIDIA GPUs for inference because of this advantage. The hardware might say “we’re 30% faster,” but once you factor in optimized drivers, libraries and scheduling, NVIDIA often beats expectations. Don’t be fooled by a champion on paper if it can’t lap the actual workload.
Key Point: Real throughput depends on the whole stack. Always benchmark end-to-end. Right now, NVIDIA’s ecosystem unlocks the most speed for the broadest range of models.
The Memory Wall and Attention Tricks
A common trap: thinking only in FLOPs. Inference is memory-bound. If a GPU can do 1000 TFLOPS but only feed it 300 GB/s, it will starve. Every generation step moves massive attention matrices in/out of DRAM. This is the notorious memory wall: chips idle waiting on data. In fact, experts note that real inference throughput scales with memory bandwidth, not just compute. In other words, if data can’t arrive fast enough, those extra cores do nothing.
The good news: clever algorithms can break the wall. For instance, FlashAttention reorders the attention math so it only touches each data block once, storing intermediate results in fast on-chip memory. It’s like moving a mini-fridge of key ingredients onto the chef’s counter instead of running to the pantry for every pinch of spice. In concrete terms, FlashAttention loads small “tiles” of tokens into SRAM, does all the attention work there and writes back results. The result: ~2-4× speedup on the attention step, with no loss of accuracy. FlashAttention-2 goes even further (up to 9× speed vs naive code), but the principle is the same: minimize DRAM traffic.
FlashAttention is like a chef who keeps a bowl of spices on the counter so he doesn’t run back to the pantry for every recipe. By keeping often-used data close at hand, he cooks many more dishes at the same time (2-4× faster).
Key facts:
- FlashAttention: Tiles attention into GPU cache, cutting memory I/O by ~75%.
- Speed Gains: ~2-4× faster than standard attention kernels (and FlashAttention-2 doubles that).
- Takeaway: Any model can use this trick - no architecture change needed. Make sure your inference engine (TensorRT-LLM, vLLM, FlashAttention kernel, etc.) includes it.
Another critical trick: KV caching. In auto-regressive generation, naively the model reprocesses every past token for each new word. That’s like rereading the entire page before writing one more sentence. KV caching tells the model to remember its past computations. All the “keys” and “values” from previous tokens stay in GPU memory, so you only compute attention for the new token.
Without KV cache, each new sentence means re-reading the whole book from page 1. With KV caching, you put a bookmark at the end of the last page and only read the new pages. Much faster!
This one change can halve the work during generation. Modern frameworks (Hugging Face, vLLM, etc.) all rely on KV cache. In practice, enabling KV cache often gives more speedup in long dialogues than switching to a hypothetically faster GPU.
Tip: Always enable KV caching and avoid systems (or API setups) that force stateless decoding.
Quantization & Batching: Squeezing Every Drop of Efficiency
Once hardware and attention kernels are primed, the next lever is precision and batching. Quantization is the compression knob. Converting weights from FP16/FP32 down to INT8/INT4 cuts model memory by ~75%-80%. New hardware (like NVIDIA’s FP8 tensor cores) capitalizes on this. Think of it as saving an image as a JPEG: you throw out some precision but keep 95% of the important detail.
Quantizing a model is like zipping a big image. A photo might go from 1000 KB to 250 KB with hardly any visible blur. In LLMs, going from 16-bit to 4-bit uses ~75% less memory while mostly preserving answers. (read here)
In cost terms, a 4-bit model can run on a much smaller GPU (sometimes even on a desktop card instead of a data‑center A100) for a fraction of the price. Enterprise reports show typical inference cost/performance improvements of 2x-4x from aggressive quantization, depending on the use case.
Don’t forget batching. Serving one request at a time leaves the GPU underused. Modern libraries (vLLM, NVIDIA Triton’s LLM, etc.) use “continuous batching” or tensor-parallel scheduling to pack many requests together. This can multiply throughput by 5-10x without buying any new GPU. Concretely, if you switch from naive sequential serving to an optimized batched inference server, you might serve the same load with ~80% fewer GPUs.
Quantization: 4-bit weights = ~75% smaller model ⇒ lower memory, higher memory bandwidth per token.
Batching: Group tens of queries on one GPU - throughput multiplies 5-10x.
These software moves often yield bigger cost cuts than even a new GPU generation. Don’t skimp on them.
The Hidden Infrastructure Tax
Finally, remember: the GPU is only part of the story. Inference clusters incur hefty infrastructure costs - networking, cooling, management - that often dwarf the hardware spend over time. Reports typically show hardware is only ~40% of total 5-year TCO; the rest (60%) goes to power, networking, racks and people.
A stark example: if you build a 512-GPU AI cluster, choosing Ethernet/RoCE networking instead of InfiniBand can save about $2.24M over 3 years. That’s the difference between buying 64 more H100 GPUs vs. scrambling for budget. This is mostly because Ethernet switches and optics cost roughly half of InfiniBand for comparable speed and use far less power.
NVIDIA’s newest GPU is like a race car, but if your data center’s network is stuck in traffic (slow or expensive), that car just idles. Spending 10% more on fiber/lower-power cables can prevent 100% more money from burning up in electricity bills.
Key points:
- Networking: For most commercial clusters, Ethernet (with RDMA/RoCE) delivers ~85-95% of InfiniBand performance at ~50% of the cost. Use InfiniBand only if your workload truly needs ultra-low-latency (and you can afford it).
- Power & Cooling: High-density GPUs need liquid cooling or industrial AC. Oversubscribing air-cooled racks can cut throughput 15-20% per industry tests (not to mention extra fan power). Plan HVAC from the start.
Tallying it up: even if you get every token processing as fast as possible in-code, a lazy infra stack will eat your gains.
Putting It All Together:
How should a savvy AI team use these insights? Here’s a quick rubric:
Compute Selection: Choose hardware with both power and proven ecosystem support. For most LLM inference today, that means NVIDIA GPUs (H100/B200) or equivalent high-end cards. Resist the temptation of new accelerator hype unless your workload is fixed. If your model changes or you need cross-compatibility, a versatile GPU is safer.
Memory & Software Optimizations: Implement FlashAttention (or equivalent tiled attention) and KV caching in your inference stack. These are free speedups. Use a well-optimized runtime (TensorRT-LLM, vLLM, FasterTransformer, etc.) that auto-batches and uses kernel fusion.
Precision & Batching: Quantize your model aggressively (FP8/INT4) and pack queries. A 4-bit model with continuous batching may run on the same hardware at 4× the tokens/second. Even if accuracy drops slightly, you can often compensate by model or prompt tuning.
Networking: Model the full 5-year TCO, not just sticker price of GPUs. For mid-sized clusters (256-1024 GPUs), default to Ethernet/RoCE unless you have strong latency SLAs. Budget ample cooling and redundancy
Ops & AI Control Plane: Invest in observability: as your stack fragments, an AI control plane is essential to track which optimizations are actually saving money.
In short, do more with less. The teams who win at AI inference will be those who spot every inefficiency and kill it - not those who buy the biggest batch of cards.
Don’t be fooled: the next leap in AI won’t come from a new chip alone. It will come from stacking dozens of small optimizations - kernel tricks, caches, precision hacks and smart infra - until you’ve turned your cluster into a lean, mean inference machine. In other words, the “fastest” AI system is the one doing the least unnecessary work.
If you remember one thing from this deep dive: build your inference pipeline like a marathon runner, not a sprinter. Work smarter at every step and your throughput and ROI will soar.
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.
