Tool-Calling LLMs Have the Same Risk Profile as Production Backends
Why prompt filters are no longer enough once AI can act, call tools and persist memory.

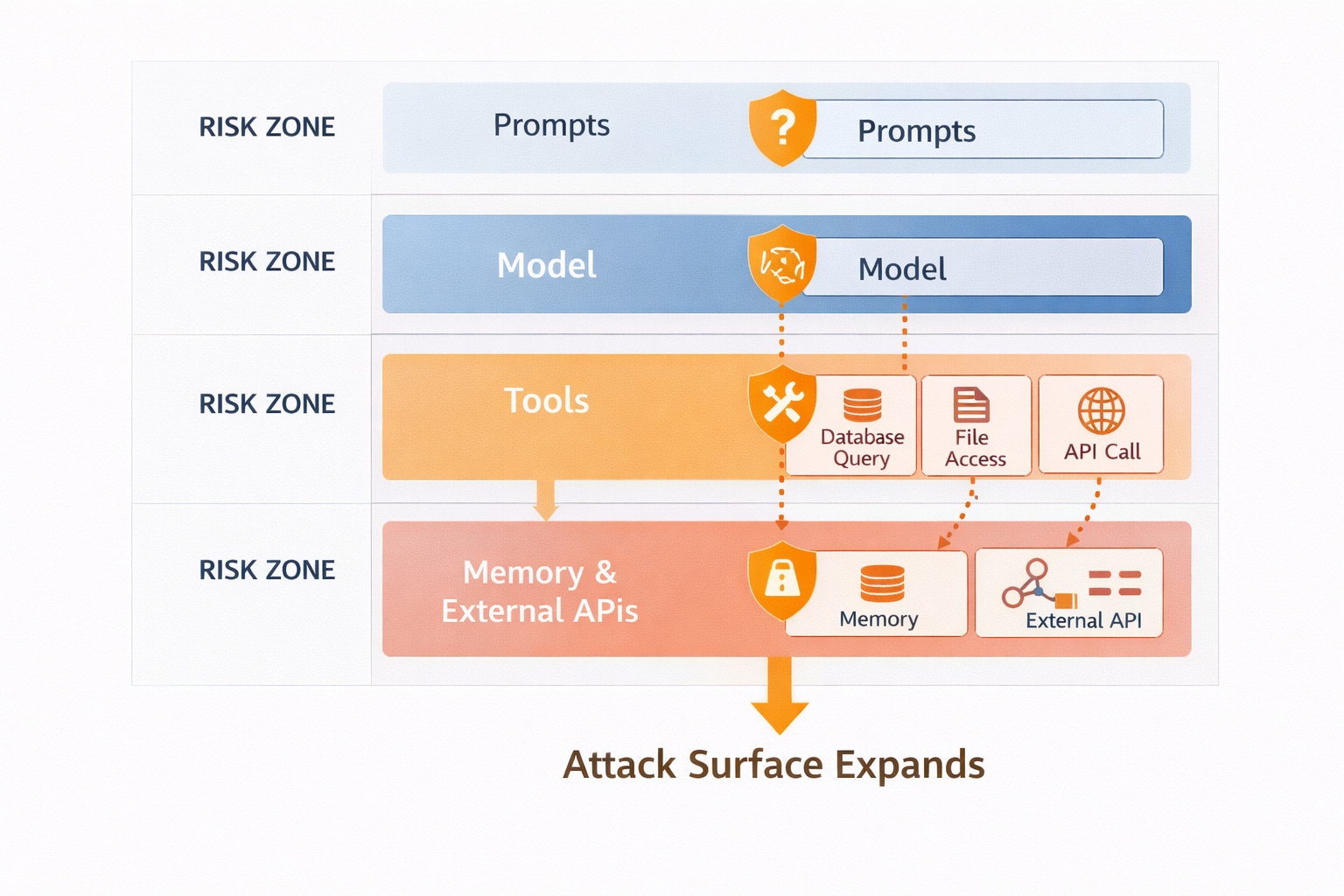
Most discussions about AI security still focus on prompts: filtering bad input, blocking disallowed content and preventing jailbreaks.
That approach is already obsolete.
Modern GenAI systems do not just generate text. They:
Query databases
Call APIs
Read and write files
Interact with internal services
At that point, an LLM is no longer just a model. It is a controller.
And controllers must be secured like any other piece of infrastructure.
Why tool calls are the real attack surface
When a model can call a tool, it is effectively issuing commands. The arguments it passes to that tool can:
Include sensitive data
Influence queries
Trigger side effects
If those arguments are derived from untrusted input, you have created a classic injection vulnerability - just with an LLM in the middle.
Prompt injection is no longer about tricking the model into saying something. It is about tricking the system into doing something.
That is a fundamentally different risk profile.
Why memory makes this worse
Memory introduces persistence. A single bad instruction can:
Be written to state
Influence future decisions
Propagate across sessions
A corrupted memory entry can turn into:
Repeated data leaks
Repeated bad tool calls
Long-lived compliance violations
Without audit trails and controls around memory, teams cannot even tell when this has happened.
What security actually requires
In agentic systems, security must operate at the same places it does in traditional systems:
at API boundaries
at data access
at state mutation
at execution time
You need:
Policy-gated tool calls
Logs of what was invoked
Records of what was written to memory
And the ability to reconstruct decisions
Filtering text is not enough.
Open question
If one of your agents were compromised by a malicious prompt today, would you be able to see what tools it called and what data it touched - or would that activity be invisible?
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.