Why the Explosion of LLMOps Tools Is Making GenAI Harder - Not Easier
As GenAI teams adopt more LLMOps tools, fragmentation is creating blind spots in quality, cost and governance. Learn what to evaluate before building or buying your LLMOps stack.

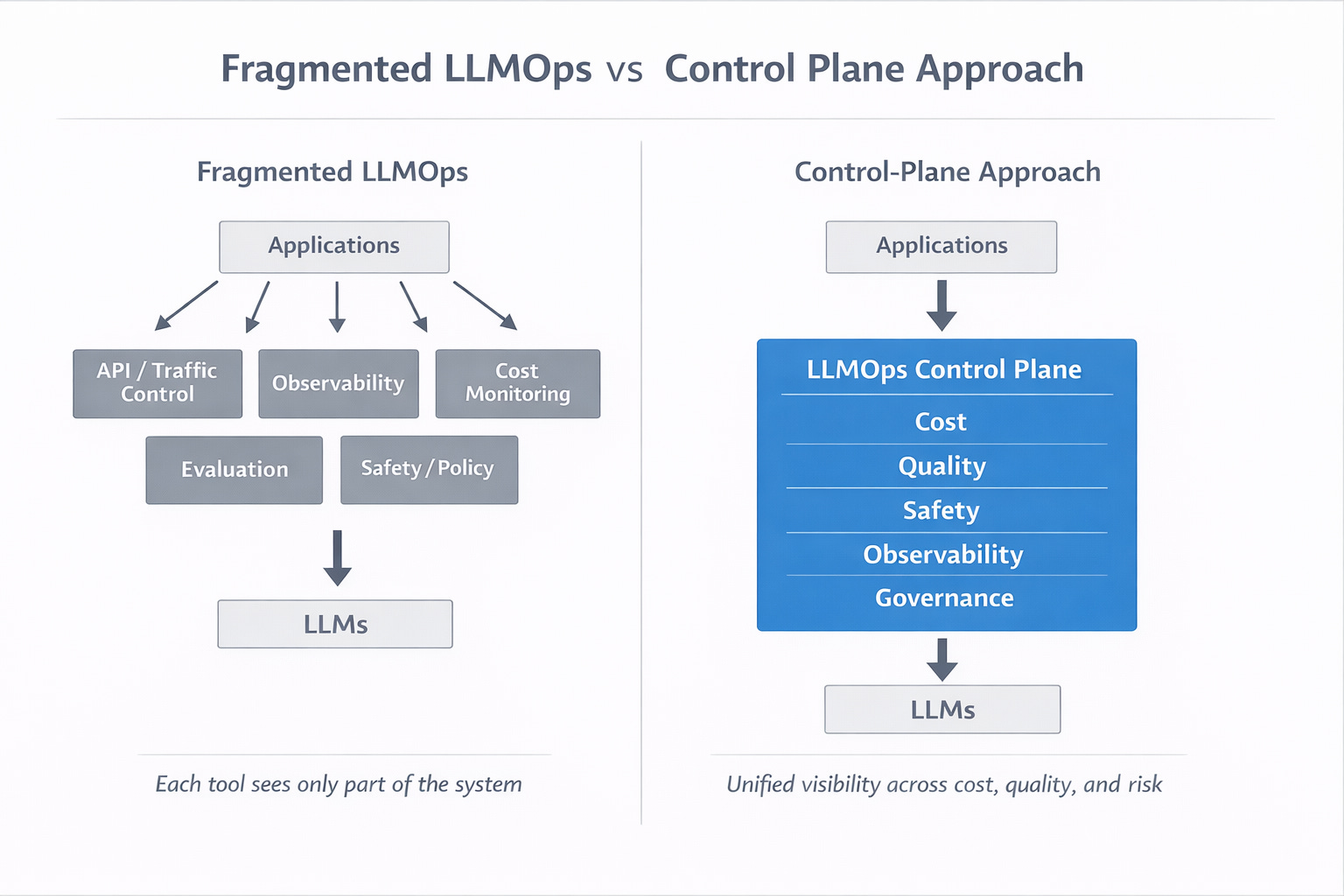
Over the last 18 months, GenAI teams have gained access to more tooling than ever before.
Gateways
Observability layers
Prompt managers
RAG frameworks
Evaluation harnesses
Cost dashboards
Safety filters
Model routers
On paper, this looks like progress.
In practice, many GenAI teams are discovering the opposite: the more tools they adopt, the harder their systems become to reason about, debug, govern and scale.
LLMOps is entering the same phase DevOps did a decade ago - the phase where tool sprawl starts to work against reliability rather than enabling it.
The Hidden Cost of Too Many LLMOps Tools
Most LLMOps tools are well-designed - but narrowly scoped.
Each solves a specific problem:
Routing requests
Tracking usage
Logging prompts
Measuring quality
Blocking unsafe outputs
Optimizing cost
The challenge is not the tools themselves.
The challenge is what happens between them.
GenAI systems are not linear pipelines. They are adaptive, probabilistic systems where behavior emerges from the interaction of models, prompts, retrieval, policies, traffic patterns, user feedback and cost constraints.
When each concern is handled by a separate tool, teams lose the ability to answer basic questions like:
Why did output quality degrade this week?
Which change caused costs to spike?
Is this a model problem, a data problem, or a prompt problem?
Are we compliant right now - not just on paper?
These questions require cross-cutting visibility, not isolated dashboards.
The Major LLMOps Capability Buckets (and Their Limits)
To understand why fragmentation is happening, it helps to look at LLMOps through capability buckets rather than tools.
Most GenAI stacks today include some combination of the following:
Traffic and API Control
Handles authentication, rate limiting, retries and routing.
Excellent at keeping traffic flowing.
Blind to semantic correctness, grounding quality and safety risk.
Observability and Telemetry
Captures logs, traces and metrics.
Explains what happened, not whether the output was right or useful.
Lacks semantic context.
Cost and Usage Monitoring
Tracks tokens, spend and usage trends.
Rarely explains why costs changed.
Usually reactive, not predictive.
Evaluation and Quality Monitoring
Measures correctness, grounding, or consistency.
Often offline or periodic.
Difficult to tie directly to production behavior.
Safety and Policy Enforcement
Blocks known risks and patterns.
Struggles with context-sensitive or emergent behavior.
Failures often surface after deployment.
RAG and Data Lineage
Manages retrieval pipelines and vector stores.
Optimizes relevance.
Rarely tracks long-term semantic decay or drift.
Model Routing and Experimentation
Balances cost, latency and accuracy.
Introduces new failure modes when not governed centrally.
Each capability is necessary.
None of them, on its own, is sufficient.
Where Fragmentation Starts to Hurt
As GenAI systems mature, teams begin to encounter following failures that do not belong to any single tool:
Quality degrades, but no alert fires.
Costs rise, but usage appears unchanged.
Retrieval accuracy drops, but embeddings look healthy.
Safety incidents occur despite policy enforcement.
Users complain before dashboards do.
The root cause is rarely isolated.
It lives at the intersection of prompt changes, model updates, data evolution, traffic patterns, policy shifts and user behavior.
Fragmented tooling forces teams to:
Manually correlate signals
Export data between systems
Debug across dashboards
Rely on intuition instead of evidence
At scale, this approach breaks down.
The In-House Question: Can GenAI Teams Build This Themselves?
Faced with fragmentation, many GenAI teams consider building an internal LLMOps platform.
On the surface, this feels reasonable.
But the true scope is often underestimated.
A production-grade in-house LLMOps platform must handle:
Semantic telemetry, not just logs
Drift detection across models, embeddings and data
Continuous quality evaluation tied to production traffic
Cost attribution at prompt and feature level
Safety enforcement with auditability
Governance workflows across teams
Regulatory compliance with lineage and controls
Adaptive routing without destabilizing quality
Each of these is a system in itself. More importantly, they are never endings because:
Models change
Data evolves
Regulations tighten
User expectations rise
What begins as a six-month effort often becomes a multi-year operational burden - competing directly with shipping the GenAI product itself.
The Emerging Reality of LLMOps
GenAI infrastructure is quietly converging toward a familiar pattern.
Not a collection of tools - but a control plane.
A layer that:
Sees across models, prompts, data and users
Connects quality, cost and risk
Enforces policies consistently
Provides explainability when things go wrong
Enables scale without guesswork
This is the same evolution DevOps and cloud security went through, i.e.:
Point solutions came first.
Control planes followed.
The Question Every GenAI Team Must Answer
Do we continue stitching together specialized tools and maintaining glue code?
Do we attempt to build and operate a full LLMOps platform in-house?
Or do we move toward a more integrated approach that treats reliability, cost, safety and quality as first-class concerns?
There is no single right answer.
But one thing is becoming clear:
As GenAI systems grow more complex, operational simplicity becomes a competitive advantage.
What approach are you taking - and why?
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.