You Can’t Trust What You Can’t See - Auditability in GenAI Systems
GenAI won’t scale in the enterprise without visibility, traceability and replay - not just logs.

Introduction: When Black Box Becomes Breach Risk
Traditional observability tools weren’t built for GenAI systems. Logs, traces and metrics are useful - but insufficient. The critical layer in GenAI systems is language itself - and current observability stops at the API call.
The result? Enterprises lose visibility into:
What was actually prompted
How model responses changed over time
Why outputs drifted or failed
In high-trust domains, this isn’t just inconvenient - it’s a dealbreaker.
The 3 Missing Layers of Observability
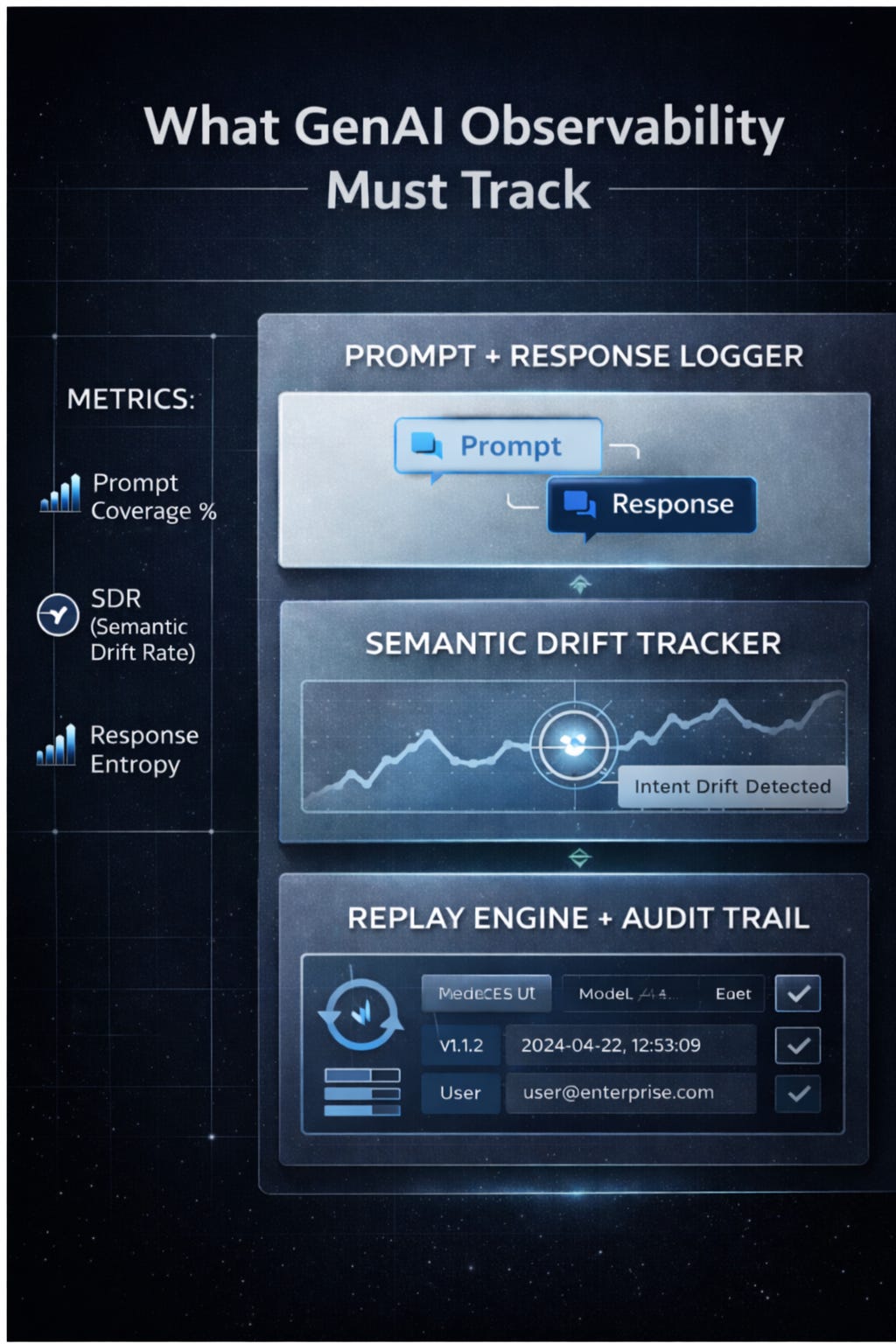
Prompt + Response Logging (with context)
Not just input/output - but with model version, time window, API route and user ID attached
Semantic Drift Tracking
Monitoring when responses for the same prompt start diverging, indicating model change or config shifts
Replayability with Provenance
Ability to reconstruct an entire GenAI transaction - prompt → model config → chain of tools → output
Without these, you cannot:
Debug failures
Respond to compliance requests
Train safety filters
Understand usage quality
Why Model Calls Aren’t Like API Calls
In traditional apps, an API request has fixed logic and deterministic behavior. Not so in GenAI.
Every call to a model is:
Non-deterministic (same input ≠ same output)
Probabilistic (subject to sampling, temperature)
Versioned (model behavior changes silently)
This makes audit trails essential. Without them, GenAI becomes untestable and untrustable.
What an Auditable System Looks Like
A trustworthy GenAI system will:
Log prompt + response pairs with semantic hash IDs
Tag outputs with source prompt + model config
Allow authorized replay with original model version or snapshot
Expose drift deltas across deployments
Support queryable logs for compliance tracebacks
Observability for Trust-Critical Workflows
Industries like finance, healthcare and legal already demand:
Explainability
Change control
Usage accountability
GenAI must meet these standards. Without them, no serious enterprise can scale LLMs into core workflows.
Key Metrics to Track
Prompt Coverage % (what % of prompts are logged and replayable)
Semantic Drift Rate (SDR) (how consistently the model answers the same question over time)
Trace Resolution Time (how fast can you answer: “Why did it say this?”)
Response Entropy Over Time (signals model/config change)
Beyond Observability: Toward a GenAI Control Plane
Observability alone only shows what happened. Control is about:
Setting policies on what should happen
Enforcing replay, retention and risk boundaries
Alerting when reality drifts from policy
Together, observability + auditability become the backbone of production-grade GenAI.
Conclusion: Trust is a System, Not a Setting
Enterprise GenAI adoption will stall unless systems become explainable, observable and auditable.
You can’t debug what you don’t see.
You can’t govern what you don’t log.
You can’t trust what you can’t trace.
It’s time to go beyond token counts and logs - and build for accountability by default.
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.