Your LLM Bill Is Not High. It Is Unexplained
Why runaway GenAI spend is really an observability failure, not a pricing problem

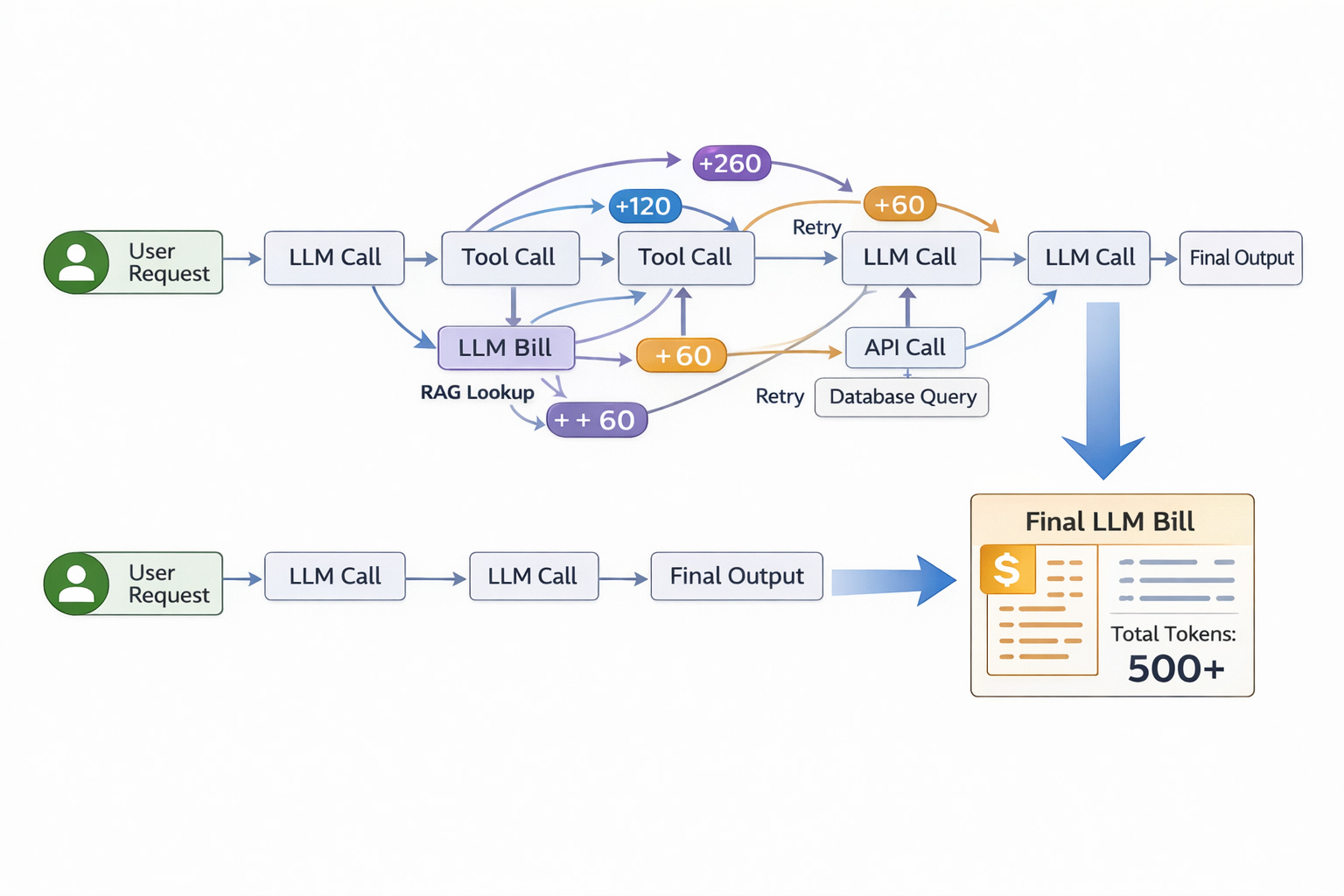
Teams across the industry are reporting the same thing: their GenAI bills feel unpredictable. One month is manageable. The next month is shocking. They switch models. They lower context windows. They add caps. The problem keeps coming back.
The reason is simple: most teams do not know what actually drives their spend.
In chat-style usage, cost roughly correlates with:
Number of users
Length of prompts
Size of responses
In agentic systems, that relationship breaks.
A single user request can fan out into dozens of hidden calls.
Where the money actually goes
In real agent stacks, most tokens are not spent on the initial prompt. They are spent on everything that happens after:
Repeated calls as the agent reasons
Tool invocations that require context re-expansion
RAG queries that pull in new documents
Fallback prompts when a step fails
Retries when a tool or API times out
Each of these steps is individually small. Together, they dominate cost.
The problem is that almost none of this is visible in standard dashboards. Teams see a total number of tokens or dollars, but they cannot see which part of the workflow produced them.
That is why cost feels chaotic. The system is operating in the dark.
Why budgets and model switching don’t work
When costs spike, teams typically respond by:
Capping usage
Downgrading models
Limiting context
Throttling users
These actions do not address the real problem.
If an agent is stuck in a retry loop, it will burn through whatever model you give it. If a tool keeps failing and triggering fallbacks, it will do so no matter how cheap the model is. If memory keeps expanding, context costs will keep rising.
Without knowing which step is responsible, you cannot optimize. You can only limit damage.
That is not cost governance. It is firefighting.
What real cost control requires
In every other distributed system, cost control is built on attribution:
Which service
Which endpoint
Which operation
Caused which cost
Agentic AI needs the same.
You need to know:
Which agent step
Which tool call
Which fallback
Caused which tokens
Only then can you:
Fix runaway loops
Optimize expensive paths
Prevent regressions
Until that exists, GenAI costs will always feel uncontrollable.
Open question
When your AI spends jumps, can you identify the exact agent step that caused it - or do you only see the final number and hope it drops next month?
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.