LLM Cost Optimization Part 3: Governance & Cost Culture for Sustainable AI
How to embed cost efficiency, ownership and metrics into your GenAI stack

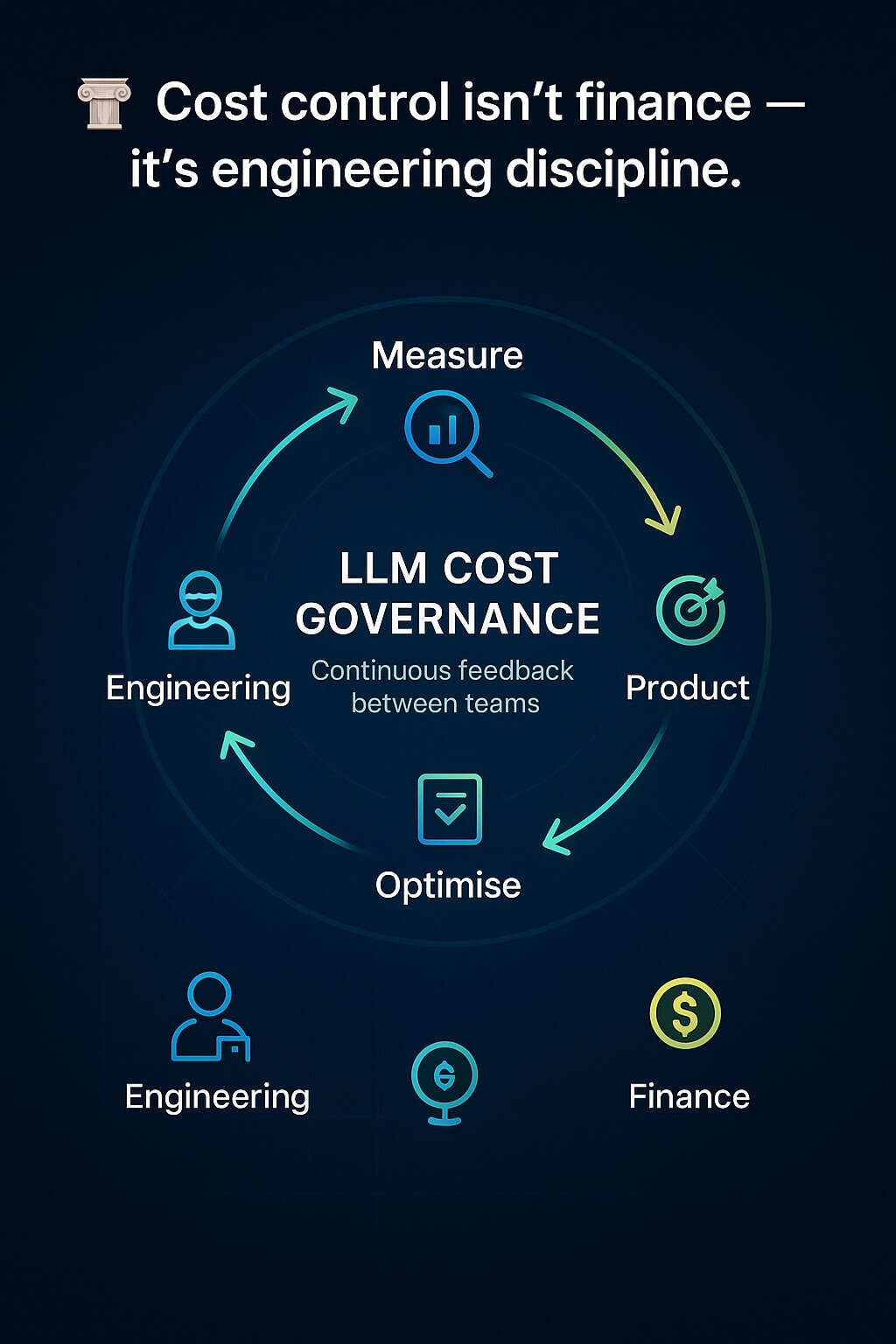
Why Governance Matters
In Part2, we discussed engineering optimization but that alone won’t save you if governance is missing. Without ownership and measurement, even efficient pipelines drift - token budgets balloon, Tier-A models overused and no one owns the spend.
This phase focuses on operationalising cost control: defining KPIs, assigning roles, implementing monitoring frameworks and establishing the culture that aligns technical discipline with business outcomes.
“Who in your organisation is accountable for cost per query and how is it measured?”
Define KPIs That Link Cost to Value
Cost Optimization only matters when tied to impact. Key metrics every AI team should track:
Cost per million tokens (input + output).
Cost per user query - normalised by product feature.
Model-tier distribution - % of Tier A/B/C usage.
Latency vs Accuracy vs Cost trade-off.
ROI per feature - cost vs value delivered(i.e. time saved or revenue impact).
A 2025 study on query routing(OptLLM) demonstrated 2.4 - 49.18% cost savings while maintaining task accuracy.
For CTOs, these KPIs become part of your regular review dashboards - just like uptime and latency in every observability dashboard.
Establish Ownership and Roles
Cost governance is a cross-functional competency - not just a DevOps problem.

Every new LLM-based feature should ship with a cost impact assessment - expected tokens use, model tier, forecast monthly cost and test-phase data.
Governance starts by making cost a required gate before production deployment.
Tooling & Monitoring Framework
Instrumentation translates uncertainty into control. Principle: Measure everything the model touches.
Recommended telemetry stack:
Per-request logging: model tier, tokens in/out, latency, outcome score, $ cost.
Dashboards: cost per 1k queries, tier-usage ratios, monthly spend trend.
Alerts: automatic notification if cost per query > threshold or Tier A usage spikes.
Integration: sync telemetry with billing and infra metrics (GPU utilisation, cloud spend).
Common Pitfalls
“We’ll optimise later.” Early design decisions lock in expensive patterns.
“Bigger model = better.” Often false; mid-tier models deliver 90-95% of accuracy for 10% of cost.
Ignoring token metrics. Without token telemetry, spend will drift unseen.
Idle infra ≠ free. Under-utilised GPUs silently eat margins.
Poor ROI linkage. If cost isn’t mapped to business output, Optimization loses meaning.
Industry analysts now treat inference cost as the next major risk vector for AI-driven products (Business Insider, 2025).
🧾 Governance Checklist
✓ Define cost KPIs per product line (cost per query, tokens per feature).
✓ Assign ownership (AI lead → models; DevOps → infra; Finance → validation).
✓ Enforce cost reporting in PRs and feature docs.
✓ Establish monthly drift reviews with engineering + finance.
✓ Integrate billing dashboards with observability stack.
✓ Set alerts for abnormal Tier A usage or token growth > x %.
✓ Train teams on prompt discipline and routing logic.
✓ Review vendor pricing quarterly for API vs on-prem break-even.
✓ Create feedback loop - cost metrics feed into OKRs.
Embedding Cost Culture
Sustained savings come from culture, not audits. Integrate cost per query into OKRs, sprint retros and release notes. Recognise teams that improve efficiency metrics.
When cost Optimization becomes a reflex, not a reactive exercise, you build financially sustainable AI systems.
Final Thoughts
For tech Small and Medium-sized Enterprises(SMEs), LLMs are both innovation and an unbudgeted risk. The difference between growth and burnout lies in discipline - treat cost as a first-class product feature.
Combine engineering tactics (model tiering, prompt compression, infra right-sizing) with governance (KPIs, roles, monitoring), teams can keep innovation affordable.
The companies that thrive in 2026 will be those that institutionalised cost optimization as a product feature, not an afterthought.
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.
Couldn't agree more. This really brings home why even the most clever engineering optimizations from Part 2 need a solid governance layer to actually stick. It makes me wonder how challenging is it to get a large organisaton to adopt these KPIs and this 'cost culture' when everyone is so focused on building new features.