LLM Cost Optimization Part 2: Engineering the Cost-Efficient LLM Pipeline
From model tiering to runtime Optimization - the architecture behind sustainable GenAI

Why This Phase Matters
In Part 1, we explored why enterprise LLM costs keep rising even as token prices fall. Now we focus on the engineering levers that actually move the needle - the technical decisions that separate an expensive demo from a cost-efficient production pipeline.
The good news: the industry has produced credible data. Significant cost savings are now achievable using model routing, token discipline and smarter infrastructure allocation. Below, we break down those levers.
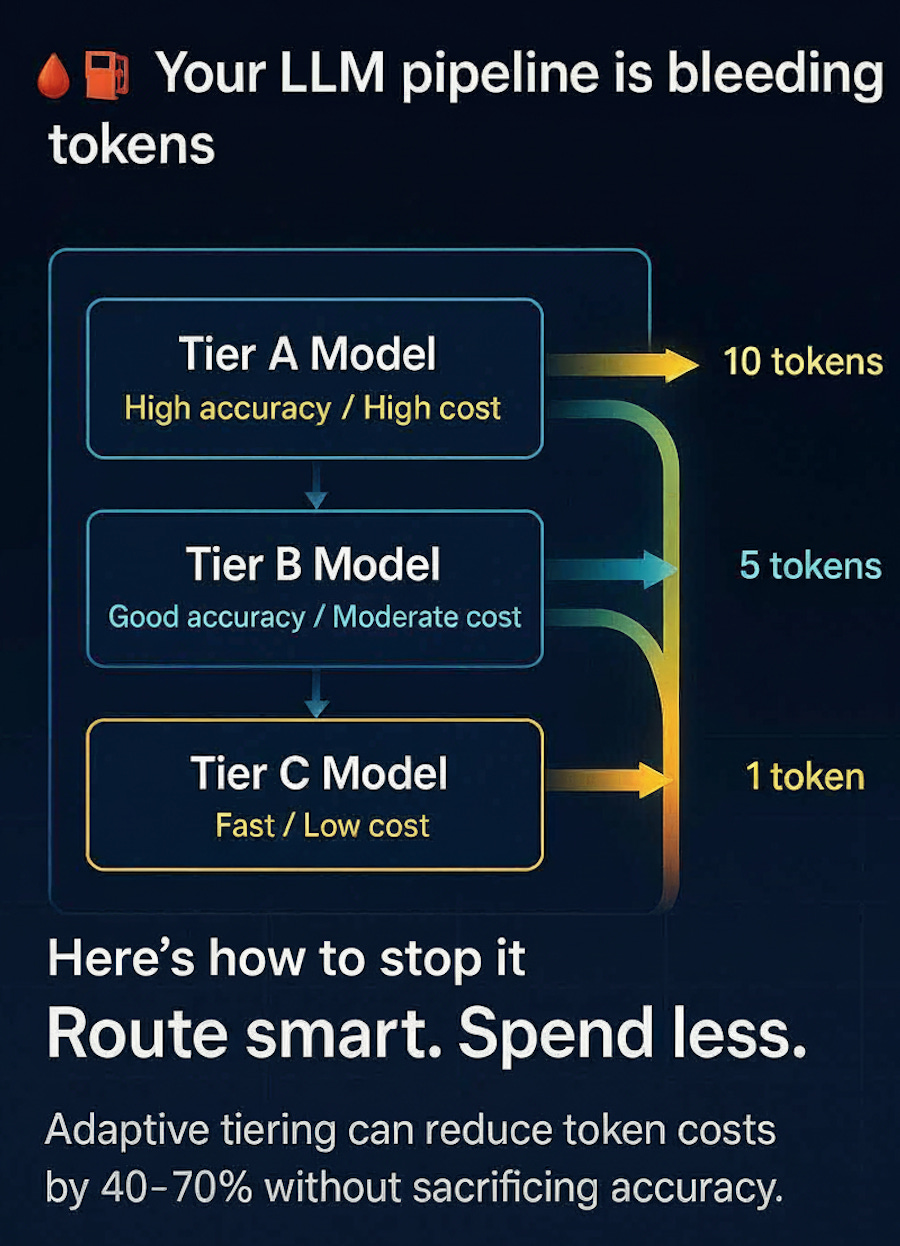
Model Tiering and Cascading Logic
A single model for all workloads is the costliest design you can choose. Research like FrugalGPT demonstrates that routing queries to smaller, cheaper models unless complexity requires escalation can reduce spend by up to 98% without measurable accuracy loss.
Another study (Routoo: Cost-Aware Model Selection, 2024) showed query-level routing reduced overall inference cost by half while maintaining quality thresholds.
Implementation guidance:
Define model tiers:
Tier A - Flagship model (highest capability, highest cost)
Tier B - Mid-range model for standard complexity
Tier C - Light/quantised model for high-volume, low-risk queries
Build routing logic: classify each query by intent or confidence, escalate only when lower tiers fail confidence thresholds.
Track cost per query: use telemetry to verify that tier distribution matches design targets (e.g., Tier A<10% usage).
Prompt Engineering, Token Trimming & Prompt Compression
Tokens are your real currency. Input and output tokens together define your invoice. Across major providers, output tokens can cost 3x of input tokens (NVIDIA Developer Blog).
Optimization steps:
Measure usage. Track average input / output tokens per request as part of real-time token telemetry.
Reuse responses. Cache deterministic results or standard prompts - typical chatbots reuse up to 40% of responses.
Trim context. Feed only the minimal RAG snippet required. Long context windows inflate cost linearly. IBM Report: LLM Token Optimization
Limit verbosity. Set max token output; summarise when full detail isn’t required.
Compression research. TRIM: Token Reduction and Inference Modeling (2024) shows reducing output by ≈20% maintains quality while saving direct cost.
Prompt Compression: While prompt trimming and reuse are well-known, prompt compression is emerging as a deeper optimization frontier.
A recent survey “Prompt Compression for Large Language Models” categorises compression into hard prompt methods (removing low-information tokens) and soft prompt methods (mapping prompt meaning into fewer embeddings) - showing high potential savings.
Another study “Dynamic Compressing Prompts (LLM-DCP)” demonstrated up to ~12.9x token-reduction for prompts while retaining performance.
Practical engineering steps:
Audit prompt length: Measure average tokens in your prompts + context.
Filter redundant text: Remove filler words, redundant instructions, verbose context blocks. In one Reddit case study: “Prompt compression… input and output token shaping… ~10-20% savings”.
Apply compression techniques:
Use template-driven rewrites to reduce clutter.
Experiment with paraphrasing policies or short-form system prompts.
Explore toolkits/libraries for advanced compression.
Measure impact: Before/after compression - tokens per request, response quality, latency, cost.
Key takeaway: Prompt compression is not just “write shorter”; it means re-encoding prompt logic more efficiently, enabling large LLMs to consume fewer tokens and reduce cost while maintaining quality.
Infrastructure & Deployment Optimization
When your Small and Medium-sized Enterprise(SME) grows, the hosting decision (API vs self-host) becomes the biggest cost lever.
On-prem vs cloud. Dell’s 2025 study found hosting a 70B-parameter model on-prem to be 4.1x cheaper than equivalent cloud API usage under stable load (Dell Technologies White Paper).
Heterogeneous GPU allocation. Mélange (2024) demonstrated that matching GPU types to request size & SLO achieved deployment cost savings of up to 77% for conversational applications, 33% for document-focused workflows and 51% for hybrid environments - all without any increase in latency.
Hybrid model. A balanced architecture: lightweight local model handles 70-80% of traffic, large API model reserved for complex reasoning or multilingual queries.
Engineering checklist:
Analyse request patterns: volume, concurrency, peak / off-peak.
Use autoscaling or spot instances to eliminate idle GPU hours.
Implement telemetry: GPU utilisation %, cost per inference job, latency vs cost graph.
Continuously evaluate break-even for external provider vs self-hosted.
Observability & Cost Feedback Loops
No optimization holds without observability. Treat cost like a first-class metric next to latency and accuracy.
Practical setup:
Instrumentation: log model tier, tokens in/out, latency, quality and cost per request.
Dashboards: cost per 1k queries, tier usage distribution, token growth trend.
Alerts: trigger when cost per query exceeds threshold or Tier A usage spikes.
Monthly review: reconcile engineering metrics with finance validating real budget impact.
Well-instrumented cost telemetry often surfaces secondary issues: inefficient RAG indexing, unnecessary context, redundant API calls or low-batch requests - leading to hidden spends.
Building a Cost-Efficient Architecture Example
Imagine a customer-support AI that handles:
70% FAQ / low-complexity questions
20% internal document search
10% strategic or cross-domain reasoning
Optimised design:
Tier C model (cheap, fast) for FAQ queries
Tier B model for document retrieval
Tier A model (premium) for strategic analysis
Shared cache for repeat FAQs and prompt templates
Token & cost telemetry dashboard linked to alerting
This yields a typical 40-60% total cost reduction without measurable quality drop.
Lessons for Builders
Start with observability. Without telemetry, Optimization is guesswork.
Right-size the model. Bigger ≠ better; route intelligently.
Own your token economy. Token budgets are your AI’s fuel budget.
Automate feedback. Integrate cost dashboards into DevOps and FinOps loops.
Educate teams. Cost awareness should live in product reviews, not just infra check-ins.
Next in the Series
Part 3 looks beyond engineering into governance and roadmaps - how to embed cost KPIs, ownership and review cycles so savings persist as deployments scale.
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.