The Hidden Complexity of Scaling GenAI Systems Part 1: The Fragility of Scale: Why AI Systems Fail Before They’re Expensive
Why reliability collapses before the bill arrives

The Paradox of Early Success
Every GenAI pilot begins the same way - the demo works, latency is sub-second, answers feel magical. Yet, when that same workload hits production, response time triples, logs overflow and teams scramble to add GPUs.
A 2025 MIT study found that 95% of AI initiatives fail to draw any return as they lag to scale beyond pilot, not because of cost but because the system breaks under its own complexity.
At FortifyRoot we call this the fragility of scale - when architectural cracks appear before cost signals do.
Hidden Failure Modes in GenAI Systems
Context Window Inflation: As features evolve, prompts balloon with redundant context, previous chats and metadata. Token length doubles, latency spikes non-linearly and output quality drifts.
Vector DB Overload: Retrieval systems, when unbounded, accumulate millions of embeddings. Search recall degrades, not because the engine is poor, but because memory pressure and index fragmentation make top-k results unstable.
Retry Loops & Queue Contagion: When responses aren’t reliable, inference fails mid-response, auto-retries trigger cascades. Each retry spawns new token requests, compounding load. As per this analysis, on an average for each request with acceptable response, you have to make at least 3 API calls to ChatGPT.
Silent Telemetry Gaps: Most enterprises lack tracing at prompt or retrieval level. Failures appear only as HTTP 500s, not which stage broke. Debugging becomes guesswork; uptime drops without diagnosis.
The Engineering Reality Behind Fragility
Reliability, not price, is the first signal of an unsustainable system. Once latency spikes or queue depth grows, engineers scale hardware blindly - compounding cost later.
Without observability, there is no way to answer:
Which feature causes the highest token drift?
How often retrieval returns empty contexts?
What latency tail (P95) triggers user drop-off?
Fragility thus precedes FinOps.
Early-Warning Signals
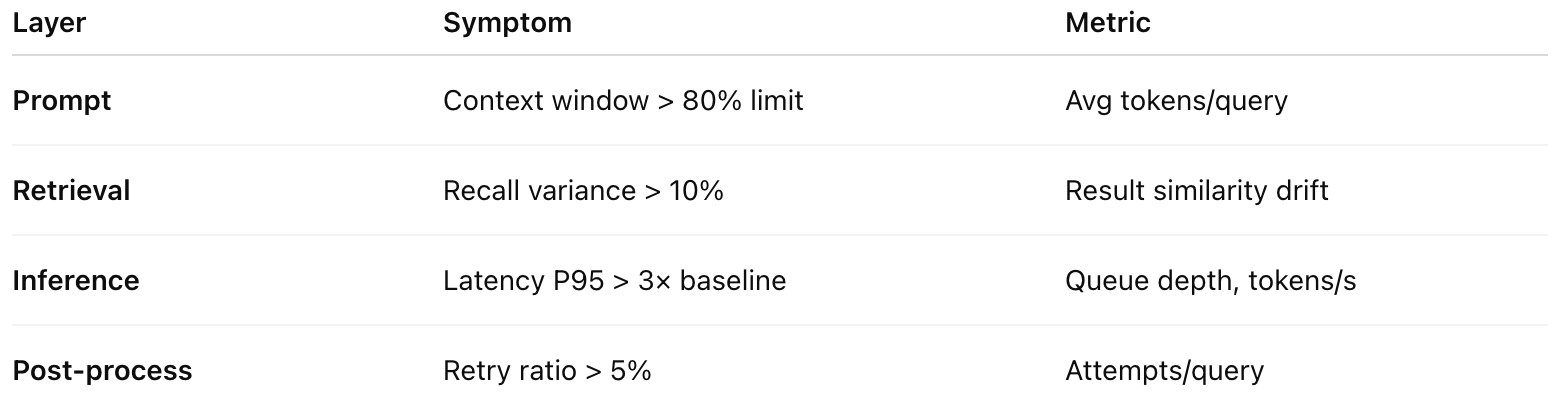
If two or more of these metrics trend upward, you’re weeks away from reliability degradation - long before CFOs notice cloud bills.
Engineering Patterns That Prevent Fragility
Build for Observability First: Instrument every stage: retrieval latency, context size, token ratio.
Circuit Breakers Everywhere: Timeouts and graceful failover stop cascading retries.
Elastic Context Policies: Trim irrelevant context via semantic filtering or chunk-scoring.
Synthetic Load Tests: Run simulated traffic spikes with tracing enabled to identify failure zones.
Cold-Path Fallbacks: If vector DB or Tier-A model fails, route to cached summary responses.
Each of these engineering interventions costs less than a single outage hour but yields exponential reliability gain.
From Pilot to Production Checklist
✅ Token growth < 10% per feature release.
✅ Latency P95 < 3x baseline.
✅ Retrieval recall > 95%.
✅ Retry ratio < 3%.
✅ Telemetry coverage > 90% of requests.
If you can’t measure these, you’re flying blind.
Leadership Lens: Reliability Precedes ROI
For CTOs and founders, the lesson is simple but non-obvious:
“You don’t lose money because AI is expensive - you lose money because AI is unreliable.”
Teams that treat reliability as a cost avoidance mechanism will spend less later on reactive infra. Teams that measure it as a business metric build trust and predictable value.
Key Takeaways
Reliability breaks before cost becomes visible.
Context, retrieval and retry loops are early failure vectors.
Observability is the first engineering investment, not a post-mortem tool.
SMEs with reliability discipline scale faster and spend smarter.
What’s Next in the Series
Part 1 exposed why GenAI systems fail before costs rise - reliability cracks hidden in context windows, vector retrieval, and retry cascades. In Part 2, we move from detection to diagnosis. We’ll explore how engineering teams can make AI systems observable - tracing every query from retrieval to response, and transforming logs into actionable telemetry. If Part 1 showed what breaks, Part 2 reveals how to see it before it breaks.
We’re FortifyRoot - the LLM Cost, Safety & Audit Control Layer for Production GenAI.
If you’re facing unpredictable LLM spend, safety risks or need auditability across GenAI workloads - we’d be glad to help.